Controllable Singing Style Conversion with Boundary-Aware Information Bottleneck
Contents
1. Abstract
This paper presents the S4 team's submission to the Singing Voice Conversion Challenge 2025 (SVCC2025)—a novel singing style conversion system designed to advance fine-grained style conversion and control under in-domain settings.
To address critical challenges such as style leakage, dynamic rendering, and high-fidelity generation with limited data, we introduce three key innovations:
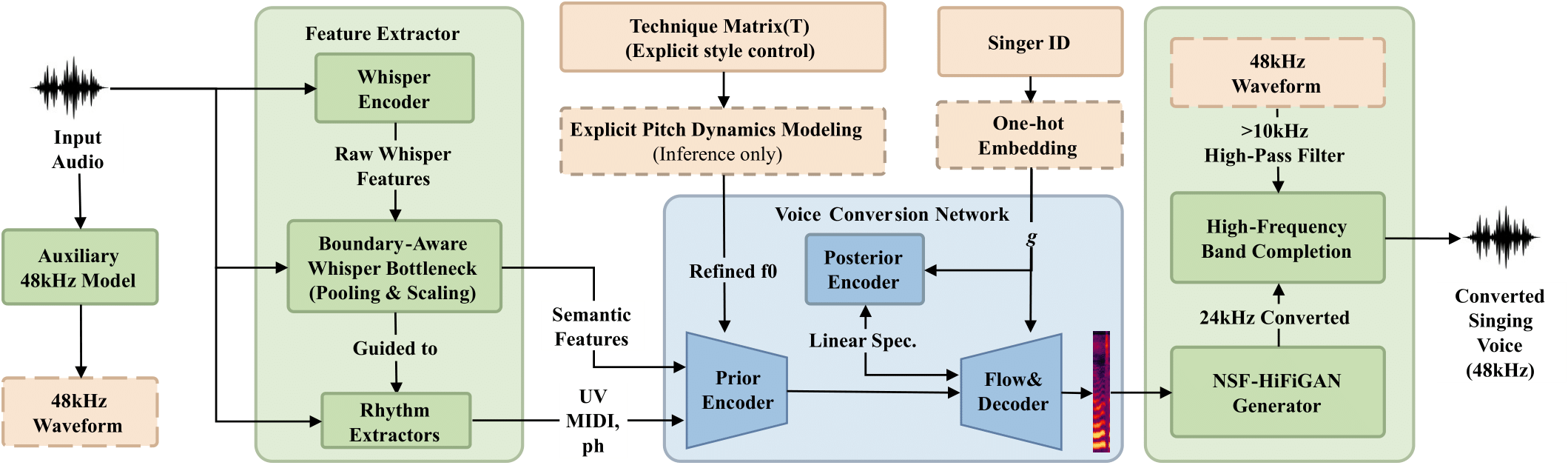
(1) Boundary-aware Whisper Bottleneck: This module pools phoneme-span representations to effectively suppress residual source style while strictly preserving linguistic content.
(2) Explicit Frame-level Technique Matrix: Enhanced by targeted $F_0$ processing at inference time, this technique ensures stable and distinct dynamic style rendering.
(3) High-frequency Band Completion: A perceptually motivated strategy that leverages an auxiliary standard 48kHz SVC model to augment the high-frequency spectrum, overcoming data scarcity without overfitting.
In the official SVCC2025 subjective evaluation, our system achieves the best naturalness performance among all submissions while maintaining competitive results in speaker similarity and technique control, despite using significantly less extra singing data than other top-performing systems.
2. Features introduction
Our system processes several key features to achieve controllable and high-fidelity singing voice conversion. The Phonemes are processed through our innovative Boundary-aware Whisper Bottleneck, which aligns SSL features with phoneme boundaries to disentangle content from source timbre.
The Tech feature corresponds to our Explicit Frame-level Technique Matrix. Unlike traditional global style embeddings, this allows for frame-level control over specific singing techniques (such as Vibrato, Glissando, etc.). The final waveform is generated using our High-frequency Band Completion strategy, resulting in 48kHz high-fidelity audio.
| Wave | Words | Phonemes | note | tech |
| <SP> there's a fire starting in my heart <AP> reaching a fever pitch and bringing me out the dark <SP> | <SP> DH EH1 R Z EY1 F AY1 ER0 S T AA1 R T IH0 NG IH0 N M AY1 HH AA1 R T <AP> R IY1 CH IH0 NG AH0 F IY1 V ER0 P IH1 CH AH0 N D B R IH1 NG IH0 NG M IY1 AW1 T DH AH1 D AA1 R K <SP> | 62 62 63 62 58 56 62 63 59 59 56 0 61 67 61 61 59 57 57 59 59 59 56 56 |
0 6 6 6 0 0 0 0 1,6 0 6 0 0 0 0 0 0 5 |
|
| finally i can see you crystal clear <AP> go ahead and sell me out and i'll lay your ship bare <AP> | F AY1 N AH0 L IY0 AY1 K AE1 N S IY1 Y UW1 K R IH1 S T AH0 L K L IH1 R <AP> G OW1 AH0 HH EH1 D AE1 N D S EH1 L M IY1 AW1 T AH0 N D AY1 L L EY1 Y UH1 R SH IH1 P B EH1 R <AP> | 65 66 65 66 65 60 59 59 65 66 62 59 0 66 68 70 64 64 63 59 59 61 62 62 61 59 59 |
1,6 1 1 1 1 1 1 0 1 1,6 1 1 1 1 1 1,6 1 1 1 1,5 |
|
| see how i leave with <AP> every piece of you <AP> don't underestimate the <AP> things that i will do <AP> | S IY1 HH AW1 AY1 L IY1 V W IH0 TH <AP> EH1 V ER0 IY0 P IY1 S AH1 V Y UW1 <AP> D OW1 N AH1 N D ER0 EH1 S T AH0 M EY2 T DH AH0 <AP> TH IH1 NG Z DH AE1 T AY1 W IH1 L D UW1 <AP> | 65 65 66 62 59 59 60 0 65 66 64 62 59 0 66 68 69 62 59 59 0 62 62 61 59 59 |
2,3 2,3,6 2,3,6 2,3 2,3 0 2,3,6 2,3 2,3 2,3 0 2,3,6 2,3,6 2,3 0 2,3 2,3 2,3 2,3 2,3 |
|
| there's a fire starting in my heart <AP> reaching a fever pitch and bringing me out the dark <SP> | DH EH1 R Z EY1 F AY1 ER0 S T AA1 R T IH0 NG IH0 N M AY1 HH AA1 R T <AP> R IY1 CH IH0 NG AH0 F IY1 V ER0 P IH1 CH AH0 N D B R IH1 NG IH0 NG M IY1 AW1 T DH AH0 D AA1 R K <SP> | 62 61 63 61 60 56 62 63 59 59 57 0 63 61 62 60 57 56 59 60 58 57 57 |
1,6 1,6 1,6 1,6 1 1 1 0 1 1 1,6 1 1 1 1 1 1 1,5 |
|
| <SP> we could've had it all <AP> rolling in the deep <AP> | <SP> W IY1 K UH0 D AH0 V HH AE1 IH0 AO1 L <AP> R OW1 L IH0 NG IH0 N DH AH0 D IY1 P <AP> | 63 66 65 63 66 67 65 0 65 62 65 62 66 67 69 66 |
2 2 2 2 2,6 0 2,6 2 2 2,6 |
3. Demos -- Technique Example
This section demonstrates the controllability of six specific singing techniques: Mix, Falsetto, Breathy, Pharyngeal, Glissando, and Vibrato. For each technique, we present a control sample (without the technique) and a target sample (with the technique applied).
| Technique Type | Control Group (Without Technique) |
Technique Group (With Technique) |
| Mixed Voice (Mix) | ||
| Falsetto | ||
| Breathy | ||
| Pharyngeal | ||
| Glissando | ||
| Vibrato |
4. Demos -- Comparison & Ablation Studies
This section presents the comparison with different upstream SSL features (ContentVec, WeNet) and ablation studies on key components, including the 48kHz super-resolution module, the pooling mechanism, and the impact of the style scaling parameter $\lambda$ (where $\lambda=0$ implies no style injection and $\lambda=1$ implies full style forcing).
| Source Speech |
Source Source Technique |
Target Target Technique |
Ours |
w/ ContentVec |
w/ WeNet |
w/o 48k SR |
w/o Pool |
$\lambda=0$ | $\lambda=1$ |
| Control | Glissando | ||||||||
| Glissando | Falsetto | ||||||||
| Breathy | Pharyngeal | ||||||||
| Mix | Vibrato | ||||||||
| Falsetto | Breathy |